0x00 前言
本文将介绍通过一种在内存中查找函数地址的方法,实现函数 GetProcAddress 的功能。
该方法最早由 Stephen Fewer 在2009年提出,metasploit 项目中几乎所有shellcode都利用该功能进行寻址。
下面将对该寻址方法进行详细的介绍。
0x01 导出表EAT的结构
在进入正题之前,让我们先了解一下导出表EAT的数据结构。
EAT的数据结构为 IMAGE_EXPORT_DIRECTORY ,IMAGE_OPTIONAL_HEADER32.DataDirectory[0].VirtualAddress 的值就是 IMAGE_EXPORT_DIRECTORY 结构体数组的起始地址(即RVA的值)。
其具体结构如下:
// 40 Bytes(0x28 Bytes)
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics; // 标志, 未用
DWORD TimeDateStamp; // 时间戳
WORD MajorVersion; // 未用
WORD MinorVersion; // 未用
DWORD Name; // 指向该导出表的文件名字符串
DWORD Base; // 导出函数的起始值
DWORD NumberOfFunctions; // 实际导出的函数个数
DWORD NumberOfNames; // 导出的函数中具名的函数个数
DWORD AddressOfFunctions; // 导出函数地址数组 (数组元素个数=NumberOfFuntions)
DWORD AddressOfNames; // 函数名称地址数组 (数组元素个数=NumberOfNames)
DWORD AddressOfNameOrdinals; // Ordinal 地址数组 (数组元素个数=NumberOfNames)
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
如下图所示,描述的是 kernel32.dll 文件的 IMAGE_EXPORT_DIRECTORY 结构体与整个EAT结构。
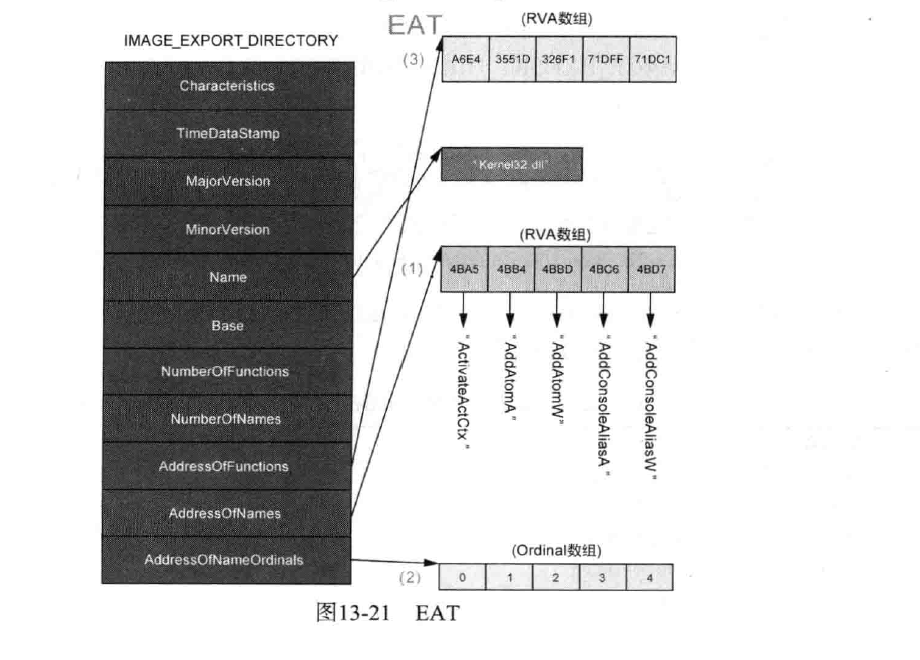
图片来自于《逆向工程核心原理》113页。
0x02 GetProcAddress() 操作原理
知道了导出表EAT的结构后,现在让我们再了解一下函数 GetProcAddress 的工作原理,这样更利于进一步了解该函数与通过Hash查找函数地址的方法的优缺点。
-
获取EAT结构的函数名称地址数组并跳转到该地址,即
IMAGE_EXPORT_DIRECTORY.AddressOfNames -
该地址处存储着此模块的所有的导出名称字符串,通过与这些字符串逐个比较(
strcmp),可以找到指定的函数名称。将此时数组的索引记作index。 -
查找并跳转到 ordinal地址数组所在的地址,即
IMAGE_EXPORT_DIRECTORY.AddressOfNameOrdinals -
在 ordinal 地址数组中利用之前找到的索引
index作为偏移量,查找对应的 ordinal 值,类似AddressOfNameOrdinals[index](实际查找的时候需要考虑到每个元素所占的大小) -
查找并跳转到导出函数地址数组所在的地址,即
IMAGE_EXPORT_DIRECTORY.AddressOfFunctions -
将刚刚得到的 ordinal的值作为数组索引,得到最终的函数起始地址,类似
AddressOfFunctions[ordinal](实际查找的时候需要考虑到每个元素所占的大小)
注: 有的模块的部分导出函数是没有函数名称的,仅有序号,因此将 index == ordinal 去处理的时候会不够准确,只有按照上面的方法去查找才不会出错。
0x03 Hash API 代码详解
0. 与其他方法相比的优缺点
通常的情况下,在内存中通过 shellcode 来进行函数名比对,来寻址到对应的API函数会浪费比较多的空间,尤其是某些函数名特别长的情况下。
某些shellcode 作者会习惯性的利用固定的模块加载顺序来寻找模块,如kernel32.dll,这种写法的优势是小巧灵活,但是在不同的环境中,如xp和win7下,引入的 kernelbase.dll 模块会导致很多shellcode失效。
而在不同的环境下 InLoadOrderModuleList ,InMemoryOrderModuleList,InInitializationOrderModuleList 这三个结构体中模块加载的顺序也不同。在不同系统中加载模块顺序不同导致 shellcode 编写很容易出问题。
通过Hash 来寻址API 其实和上面的 GetProcAddress 大体上类似,唯一的区别在于 Hash API 将函数名和模块名通过一些运算变成 Hash 值来进行查找和比较,避免了因为函数名过长而浪费大量的空间。也解决了模块加载顺序的问题,可以兼容各种平台。不过不如特定顺序寻址的方式灵活小巧。
下面将以解释汇编代码片段的形式来介绍,完整代码见 metasploit。
1. 定位 InMemoryOrderModuleList
我们在解析PEB的过程中,利用了FS 段寄存器, 在windows环境中, FS 段寄存器指向线程环境块(TEB)的地址,当在内存区运行shellcode时,我们需要从 TEB 所在的地址处移动48字节来得到 PEB 的地址,如下
api_call:
pushad ; 保存所有寄存器状态
mov ebp, esp ; 创建新的栈帧
xor eax, eax ; 将EAX清零
mov edx, [fs:eax+48] ; 将指针指向PEB
为了读者更方便的理解,TEB 的结构如图所示:
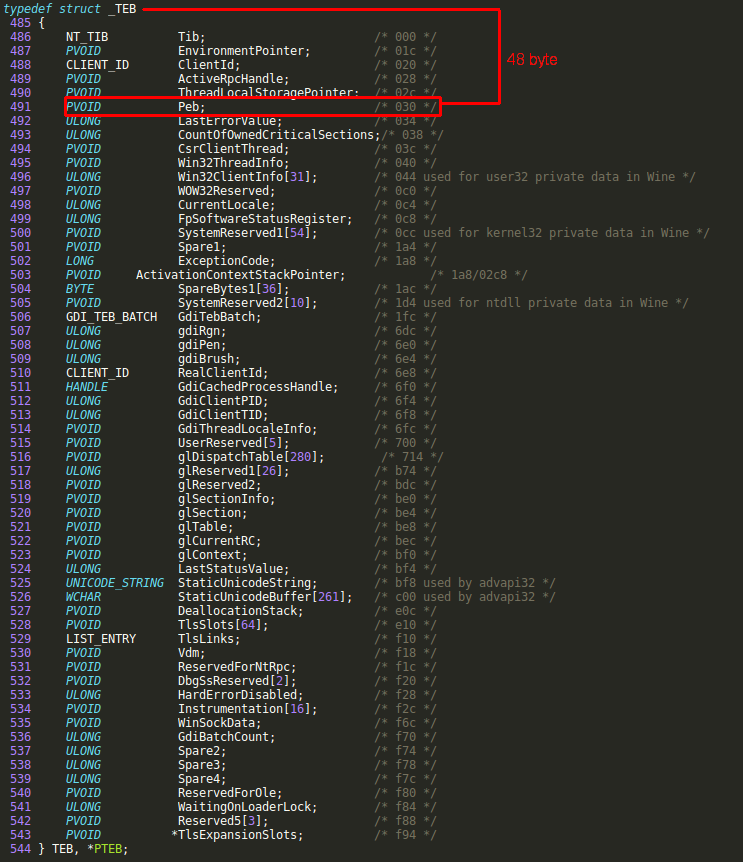
在找到 PEB 结构的地址后,再偏移12字节就能得到Ldr数据结构的地址。
Ldr 结构体包含了进程加载模块的信息,将其再偏移 20字节,我们就能从 InMemoryOrderModuleList 结构体中获得第一个已加载的模块。
mov edx, [edx+12] ; Get PEB->Ldr
mov edx, [edx+20] ; 得到 InMemoryOrderModuleList 的地址,也就是加载的第一个模块的地址
PEB的结构如图所示:
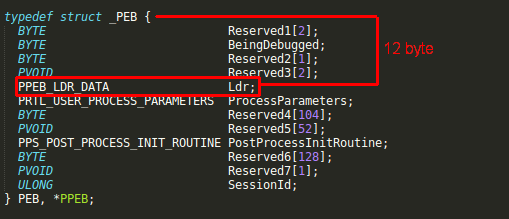
LDR结构体PEB_LDR_DATA的结构如图:

现在我们的指针指向了 InMemoryOrderModuleList ,它是一个 LIST_ENTRY 的数据结构。
LIST_ENTRY 的结构如下:
typedef struct _LIST_ENTRY {
struct _LIST_ENTRY *Flink;
struct _LIST_ENTRY *Blink;
} LIST_ENTRY, *PLIST_ENTRY, *RESTRICTED_POINTER PRLIST_ENTRY;
MSDN中对该结构体的解释为
The head of a doubly-linked list that contains the loaded modules for the process. Each item in the list is a pointer to an LDR_DATA_TABLE_ENTRY structure
即这个双向链表指向进程装载的模块,结构中的每个指针,都指向一个 LDR_DATA_TABLE_ENTRY 的结构,其中 Flink 指向后一个, Blink 指向前一个。
LDR_DATA_TABLE_ENTRY 的结构如下:
typedef struct _LDR_DATA_TABLE_ENTRY
{
LIST_ENTRY InLoadOrderLinks;
LIST_ENTRY InMemoryOrderLinks;
LIST_ENTRY InInitializationOrderLinks;
PVOID DllBase;
PVOID EntryPoint;
ULONG SizeOfImage;
UNICODE_STRING FullDllName;
UNICODE_STRING BaseDllName;
ULONG Flags;
WORD LoadCount;
WORD TlsIndex;
union
{
LIST_ENTRY HashLinks;
struct
{
PVOID SectionPointer;
ULONG CheckSum;
};
};
union
{
ULONG TimeDateStamp;
PVOID LoadedImports;
};
_ACTIVATION_CONTEXT * EntryPointActivationContext;
PVOID PatchInformation;
LIST_ENTRY ForwarderLinks;
LIST_ENTRY ServiceTagLinks;
LIST_ENTRY StaticLinks;
} LDR_DATA_TABLE_ENTRY, *PLDR_DATA_TABLE_ENTRY;
整理一下思路,即 PEB -> TEB -> Ldr -> InMemoryOrderModuleList 得到进程加载的第一个模块。
通过 InMemoryOrderModuleList 我们就能够获得进程加载所有的模块的信息了,这个结构很重要,之后我们的寻址主要靠它。
2. 计算模块Hash
继续下面的代码
next_mod:
mov esi, [edx+40] ; 获得指向模块名称BaseDllName的地址
movzx ecx, word [edx+38] ; 指向BaseDllName->MaximumLength,表示该内存缓冲区的总大小
xor edi, edi ; Clear EDI which will store the hash of the module name
[edx+40] 表示 LDR_DATA_TABLE_ENTRY->BaseDllName ,即模块名称,为UNICODE_STRING结构体。
[edx+38] 表示 BaseDllName->MaximumLength,具体可参考MSDN 中的UNICODE_STRING结构体的定义,这里就不详细讲了。
loop_modname:
lodsb ; 逐字节读取模块名,和指令 lods byte ptr ds:[esi] 效果相同
cmp al, 'a' ; 和字母'a'比较,这里是为了统一切换成大写
jl not_lowercase ;
sub al, 0x20 ; 大写则跳转,小写则变为大写
not_lowercase:
ror edi, 13 ; 将hash值循环右移13位
add edi, eax ; hash值与下一个字符相加,等到新的hash值
loop loop_modname ; 循环相加,循环次数为ecx,即BaseDllName的缓冲区大小
这里就是将字符串转换成 Hash 值的关键代码,利用 ror edi, 13 将每个字符右移13次,再与新的字符相加,重复右移,最后得到最终的 Hash 值。
这里的循环右移13次没有什么特别的含义,只是为了确保得到一个唯一的值,与Hash算法的出发点一样。 如果你愿意你可以修改一下改成自己的算法,如 左移,多重复移动几次,甚至与其他的运算混合使用,只要唯一就可以。 很多恶意软件的作者都对这个 Hash 算法进行了自己的修改以达到免杀的目的。
3. 定位模块加载基址DllBase
push edx ; 保存edx,edx的值指向InMemoryOrderModuleList
push edi ; 保存edi,edi为之前计算的模块hash
mov edx, [edx+16] ; [edx+16]为 `LDR_DATA_TABLE_ENTRY->DllBase` ,镜像加载内存中的基址
mov ecx, [edx+60] ; [edx+60] 指向 IMAGE_DOS_HEADER结构体中的e_lfanew,表示PE头的RVA地址
为了更清晰的认识这几行代码的作用,我在od里面调试了这部分代码,如图
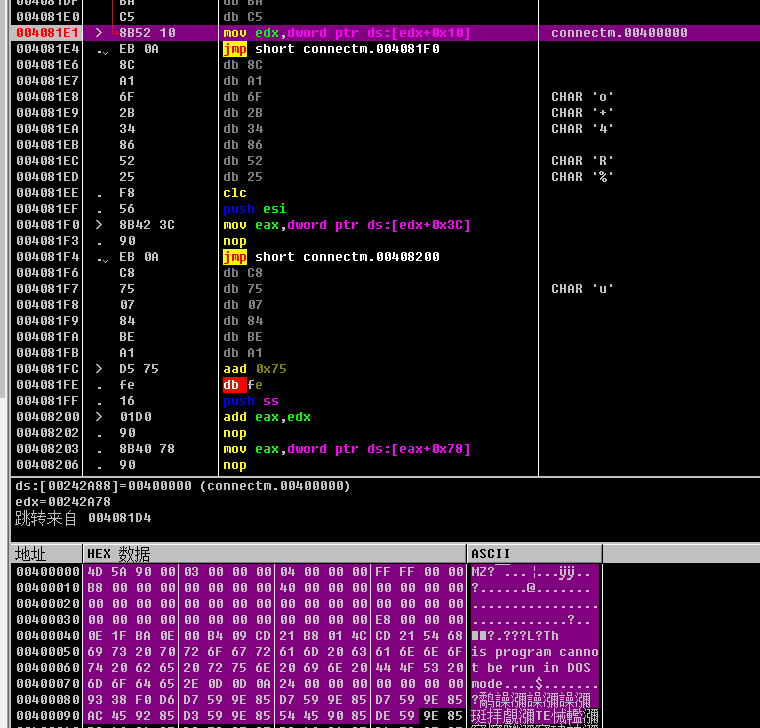
可以看到图中 ds:[edx+0x10]=00400000,即镜像加载到内存中的基址,数据窗口中可以看到明显的DOS头字符 MZ。
PE 头 结构如下图,IMAGE_DOS_HEADER->e_lfanew值为 000000E8,是PE头的RVA,在数据窗口可以看到 004000E8 的字符为 PE 。
通过PE头和DllBase我们就能获得导出函数表EAT,因为ASLR载入随机地址的原因,所以查找 DllBase 是非常重要的一个步骤。
4. 定位导出表EAT
mov ecx, [ecx+edx+120] ; DllBase+PE头RVA地址+120等于导出表EAT的RVA地址
jecxz get_next_mod1 ; ECX为0则跳转,即没有导出函数则跳转到下一个模块
add ecx, edx ; 导出地址表EAT的RVA加上模块基地址DllBase为VA
push ecx ; 保存当前模块的EAT的VA
mov ebx, [ecx+32] ; 获取函数名称地址数组 IMAGE_EXPORT_DIRECTORY->AddressOfNames 的RVA
add ebx, edx ; 函数名称地址数组 的 VA 等于其 RVA + 模块的基地址DllBase
mov ecx, [ecx+24] ; 获取导出函数中具名的函数个数 IMAGE_EXPORT_DIRECTORY->NumberOfNames
……
get_next_mod:
pop edi ; Pop off the current (now the previous) modules EAT
get_next_mod1:
pop edi ; 弹出之前的保存的模块hash
pop edx ; 还原之前保存的 InMemoryOrderModuleList 地址
mov edx, [edx] ; InMemoryOrderModuleList是链表结构,[edx]指向指向下一个加载的模块
jmp short next_mod ; 跳转到下一个模块的处理代码
导出表EAT的地址为PE头偏移120字节,即 IMAGE_OPTIONAL_HEADER32.DataDirectory[0].VirtualAddress 的RVA。
具体PE头结构组成细节请参考 PE 头文件格式,这里不再详述。其他汇编代码请参考前面的 EAT 结构。
5. 通过Hash查找目标函数
这段代码主要是在模块内遍历所有函数,计算hash,与目标函数的hash值进行比对,相等则表示成功找到。
get_next_func: ;
jecxz get_next_mod ; ECX为0,说明搜索结束,跳转到下一个模块,这里是从后往前进行搜索。
dec ecx ; ecx减一,即导出的函数中具名的函数个数NumberOfNames作为循环计数器
mov esi, [ebx+ecx*4] ; 获取导出函数的函数名字符串
add esi, edx ; 获取该 FunctionName 的 VA (DllBase + RVA)
xor edi, edi ; Clear EDI which will store the hash of the function name
loop_funcname: ;
lodsb ; 逐字节读取esi中保存的函数名称,结果放入eax中
ror edi, 13 ; 循环右移13次计算hash
add edi, eax ; 与下一次函数名字符相加
cmp al, ah ; Compare AL (the next byte from the name) to AH (null)
jne loop_funcname ; 不为空则继续循环
add edi, [ebp-8] ; [ebp-8]为之前计算过的模块hash,与这里的函数hash相加得到总的hash
cmp edi, [ebp+36] ; 与目标函数的hash值比较
jnz get_next_func ; 如果不相等,则重复查找
值得注意的是代码 mov esi, [ebx+ecx*4] ,其中 ebx 表示函数名称地址表 AddressOfNames 的VA地址,其中 ecx 作为索引,在该地址表中通过循环逆序查找所有的导出函数名称字符串,ecx*4 是因为一个函数名称占4字节,为双字储存,如图所示
如果成功找到,则修复堆栈,调用函数
pop eax ; 还原当前模块的EAT的VA
mov ebx, [eax+36] ; 获取 AddressOfNameOrdinals 的RVA
add ebx, edx ; 与DllBase相加得到VA
mov cx, [ebx+2*ecx] ; 在AddressOfNameOrdinals中获得目标函数的index
mov ebx, [eax+28] ; 获得函数地址表 AddressfFunctions 的RVA
add ebx, edx ; 与DllBase相加得到VA
mov eax, [ebx+4*ecx] ; 获得目标函数的RVA
add eax, edx ; 与DllBase相加得到最终函数的VA,
mov cx, [ebx+2*ecx] 这一行代码类似 AddressOfNameOrdinals[index] ,因为该索引值的大小为2字节,因此需要乘以2。
mov eax, [ebx+4*ecx] 是获得目标函数的RVA,即 DllBase + IMAGE_EXPORT_DIRECTORY->AddressOfFunctions) + (4 * OrdinalIndex) 。
至此就基本完成了通过Hash 寻址API的工作,剩下的就是还原堆栈,跳转到对应函数进行调用,这里就不细讲了。
0x04 总结
本文介绍了由 Stephen Fewer 提出的通过对函数进行Hash运算,来查找内存中加载的任意API地址的方法。
在 metasploit 中该方法被大量使用,值得学习。